JMeter—10小时入门版
简介
全称 Apache JMeter ,一个基于 Java 的开源性能测试工具,有些同学也用来做一些简单的接口测试,但它主要的功能是用来做性能的。
其工作原理是,建立一个线程池,多线程运行取样器产生大量负载,在运行中通过断言来验证结果的正确性,通过监听器来记录测试结果;
Github地址:https://github.com/apache/jmeter
Jmeter 组件
线程组
可以看做一个虚拟用户组,线程组中的每个线程都可以理解为一个虚拟用户;
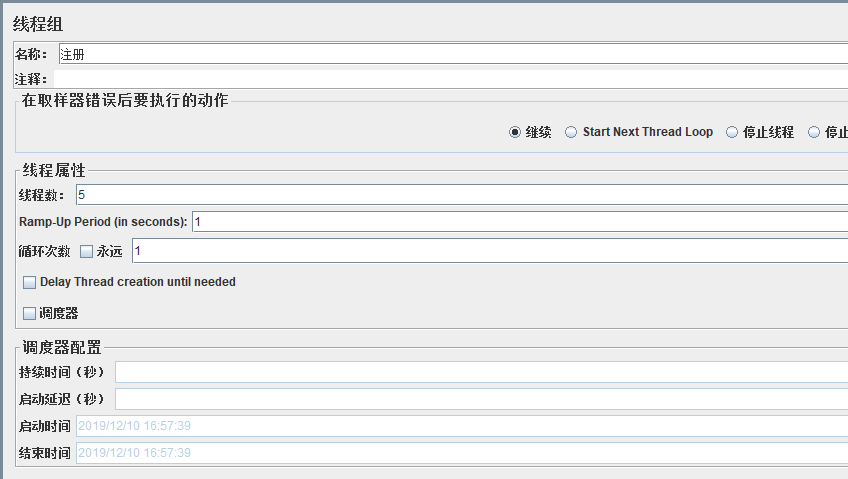
线程数就表示虚拟用户数;
Ramp-up Period 爬坡启动时间,单位是秒,默认时间是1,它制定了启动所有线程所花费的时间。
(举例:线程数10个,运行时间5,就是1秒启动2个)
取样器(sampler)
性能测试中向服务器发送请求,记录响应信息,记录响应时间的最小单元。
逻辑控制器(logic controller)
两类:
① 控制测试计划中取样器节点发送请求的逻辑顺序的控制器(if/switch/Controller)
② 用来组织可控制取样器节点的,失误控制器、吞吐量控制器。
(1)循环控制器
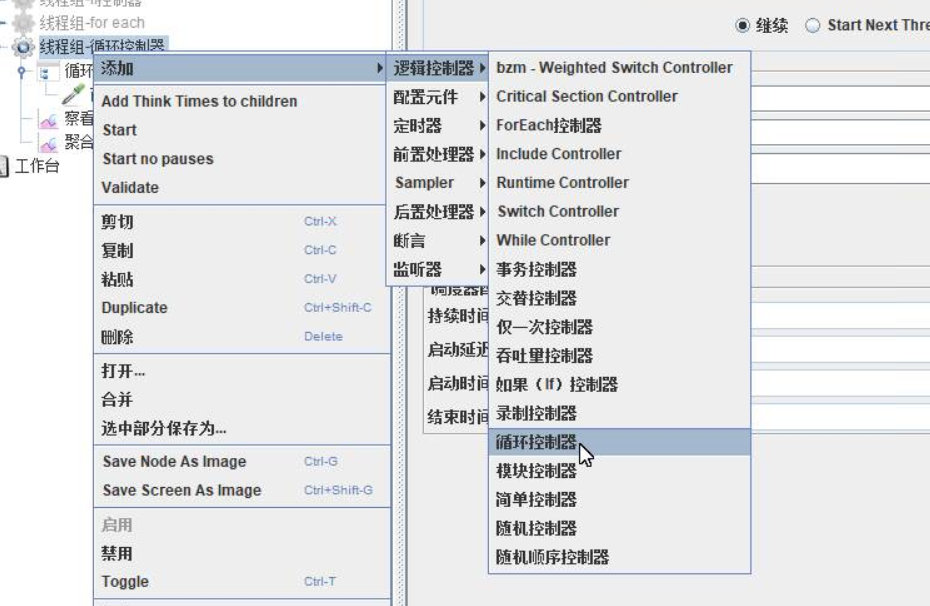
线程组循环次数与循环控制器循环次数叠加(相乘)
badboy 录制的循环控制器和 jmeter 带的循环控制器不兼容
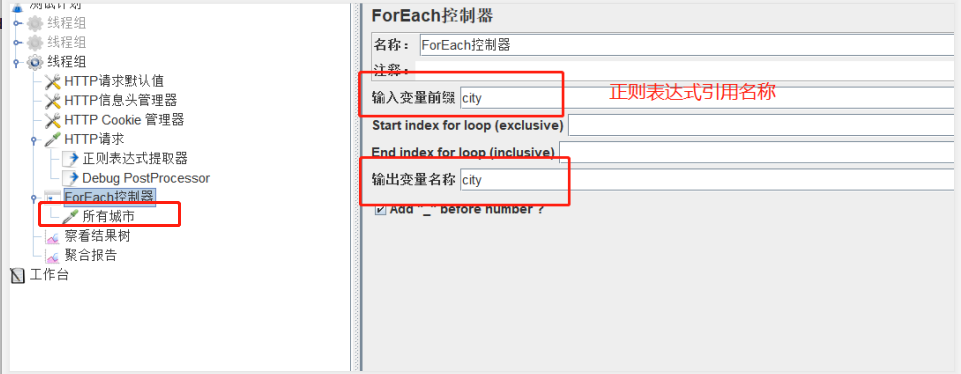
(2)ForEach控制器
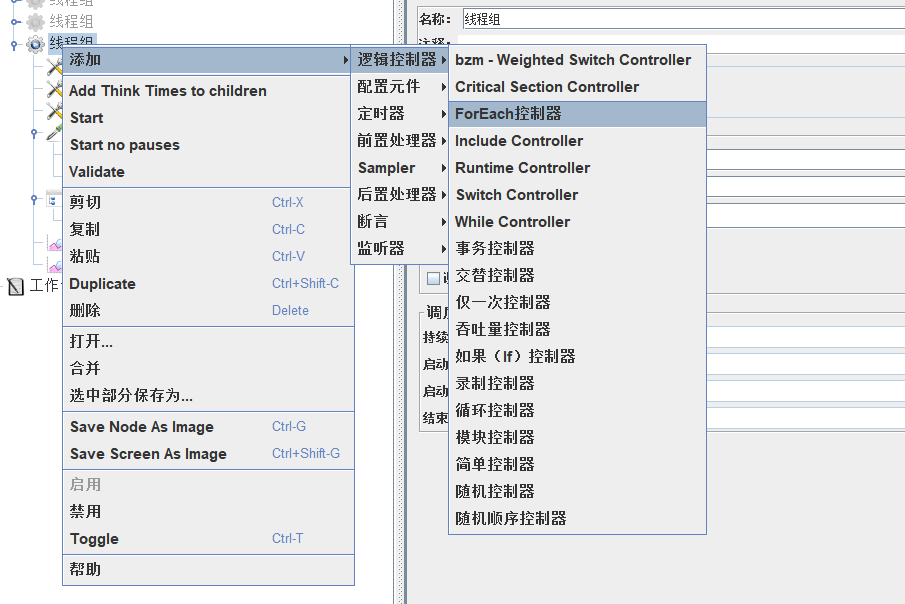
后面的请求是加在 ForEach 控制器下面
(3)If 控制器
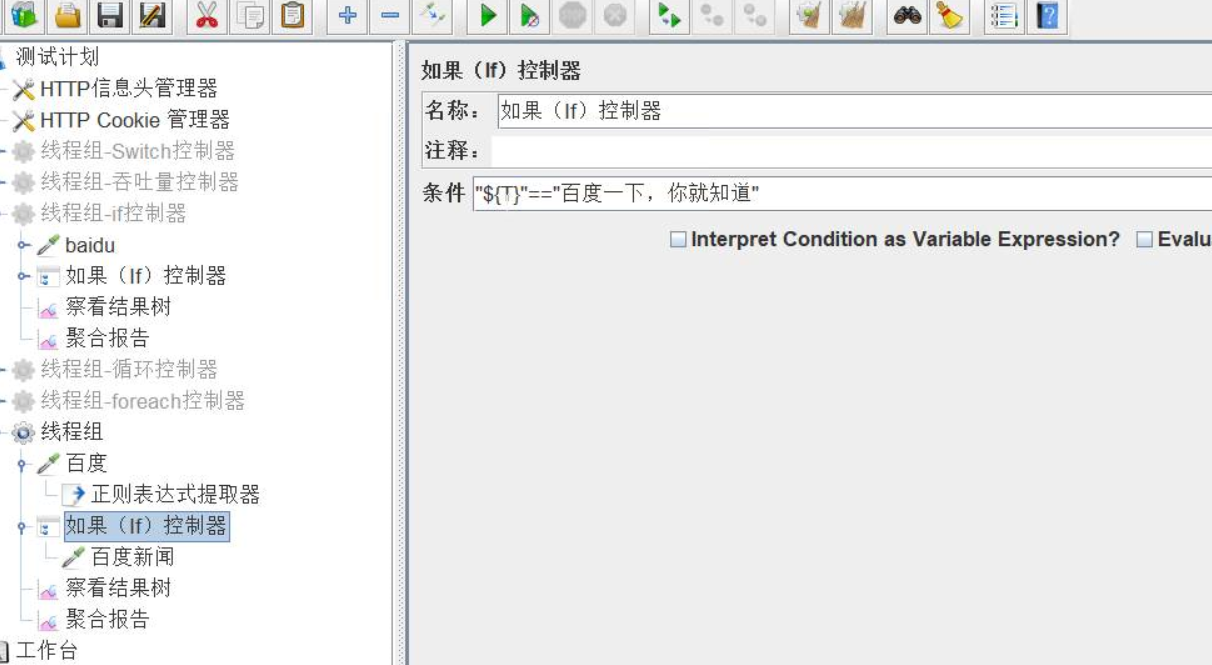
注意:条件里面,变量要用 "${}" ,if 下面加 http 请求
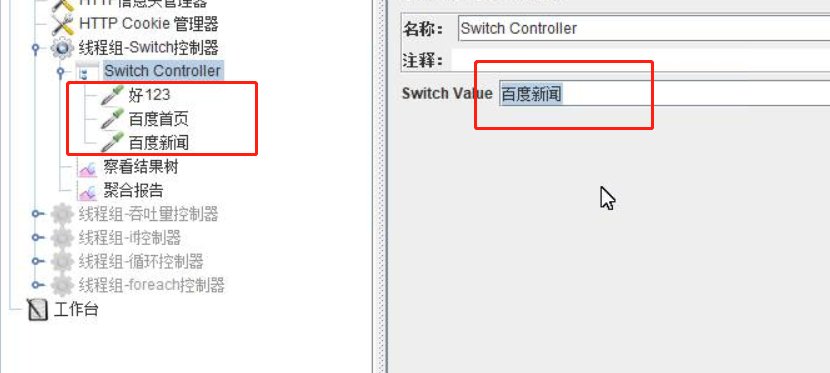
(4)switch 控制器(开关)
- 在逻辑控制器里面选择
switch controller(switch控制器) - 在控制器内添加多个请求
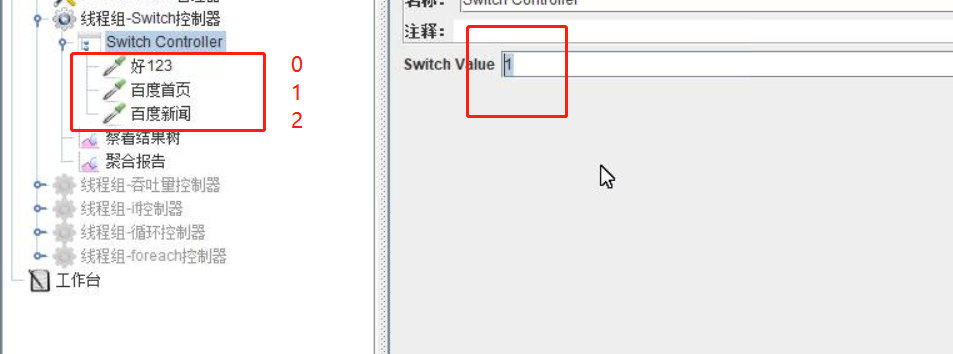
- 可通过请求名称来控制,或通过请求序号来控制(序号从0开始)
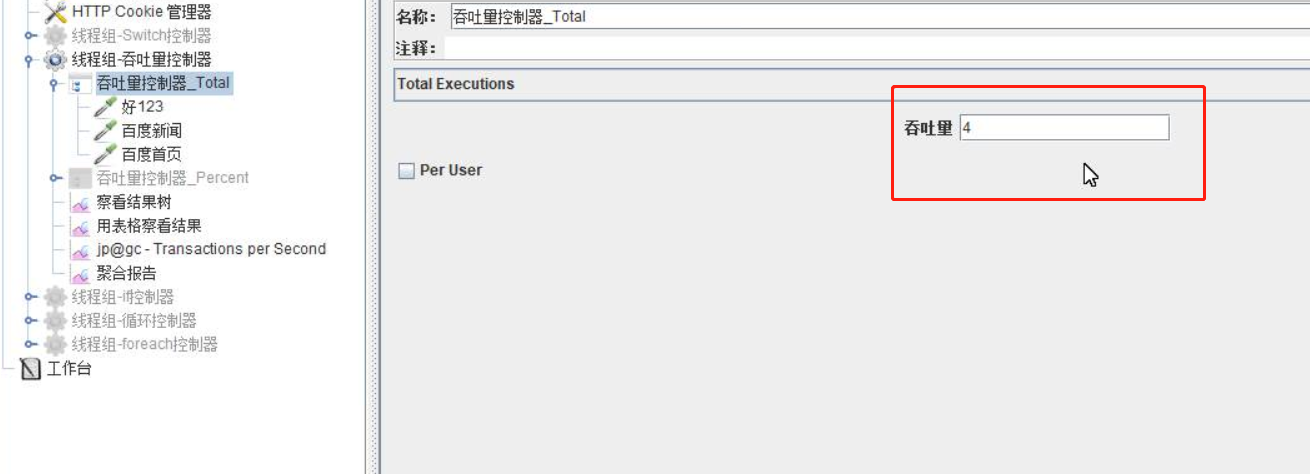
(5)吞吐量控制器
在逻辑控制器里面选择吞吐量控制器(用于控制发送的请求数)
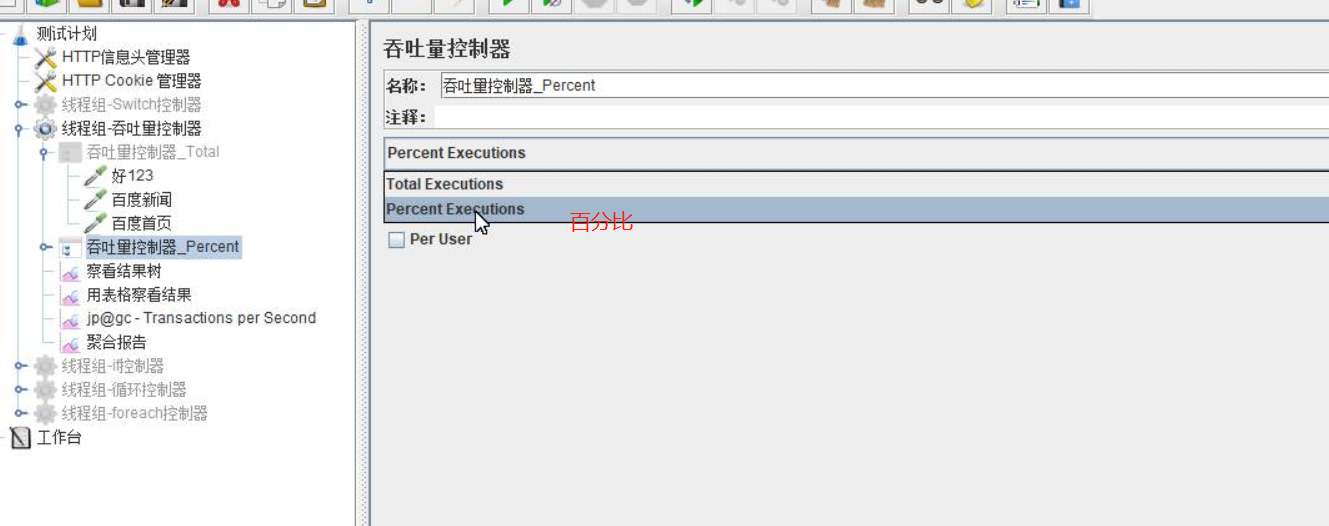
Total Executions(吞吐量)输入数据,输入数据要小于等于线程组数(每个线程发送4次,线程组数和循环次数无效)Percent Executions吞吐量百分比(线程组数10个,吞吐量百分比25,每个线程发送2次,百分比25.5,每个线程发送3次)
定时器
①固定定时器(思考时间)
每个线程在请求之前按相同的制定时间停顿。
②同步定时器(集合点)
集合点,等到特定的用户数后再一起执行某个操作。

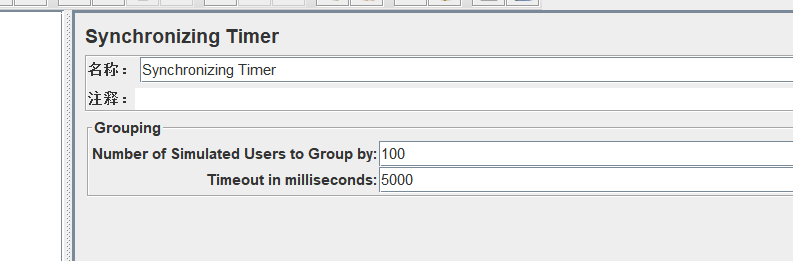
Number of Simulated Users to Group by:集合多少人后再执行请求;
Timeout in milliseconds :指定人数多少秒没有集合到算超时(延迟时间,单位毫秒);如果为0,表示无超时时间,会一直等下去。如果线程数小于集合人数,到时间就会发出去。
配置元件
用于提供对静态数据配置的支持
参数化有三种:
- CSV Data Set config
- 函数助手
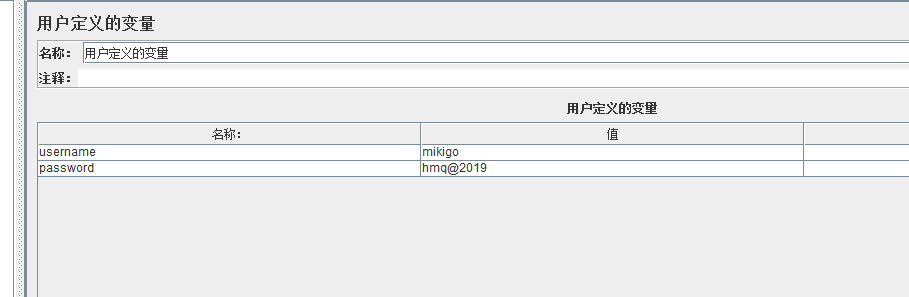
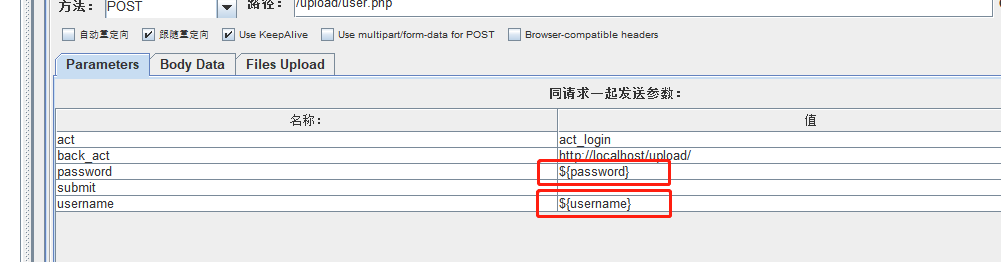
- 用户自定义变量
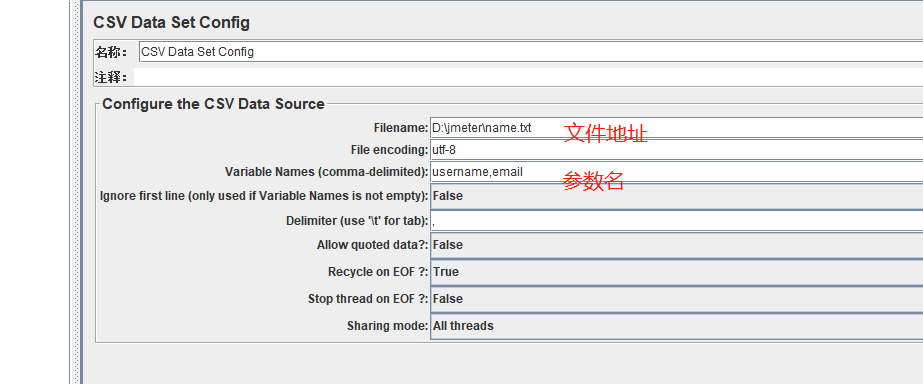
① CSV Data Set config
可以将本地数据文件形成数据池。
② 函数助手
选项-函数助手
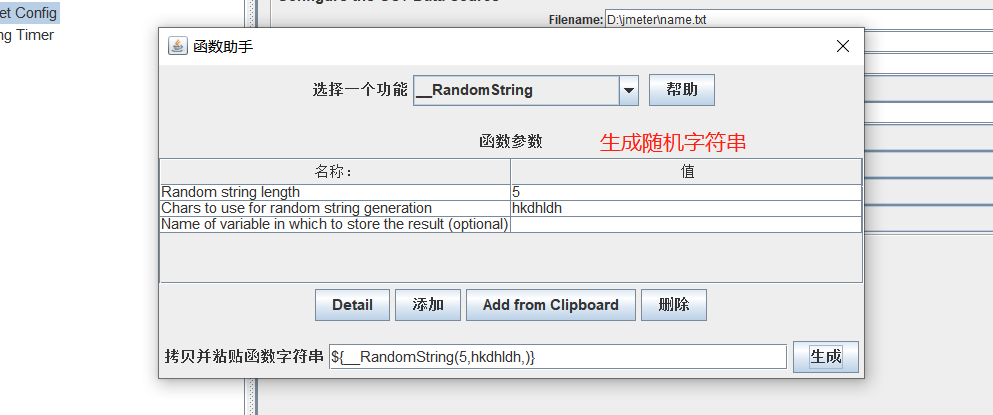
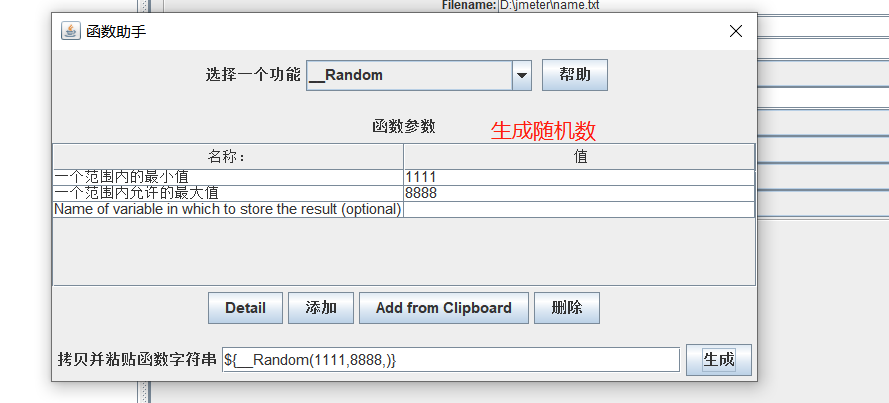
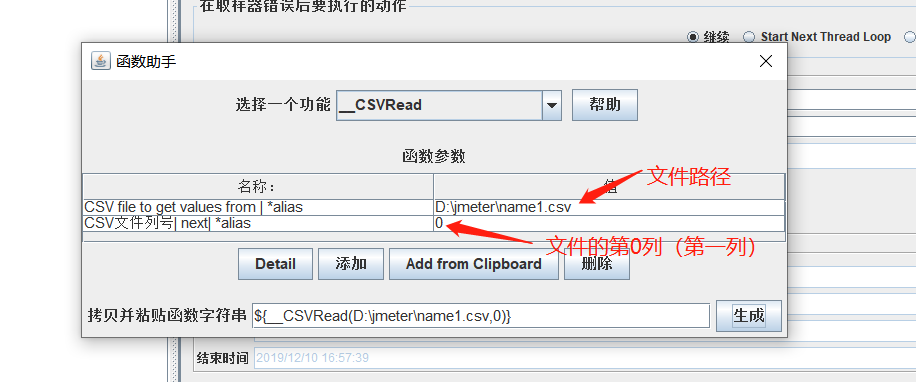
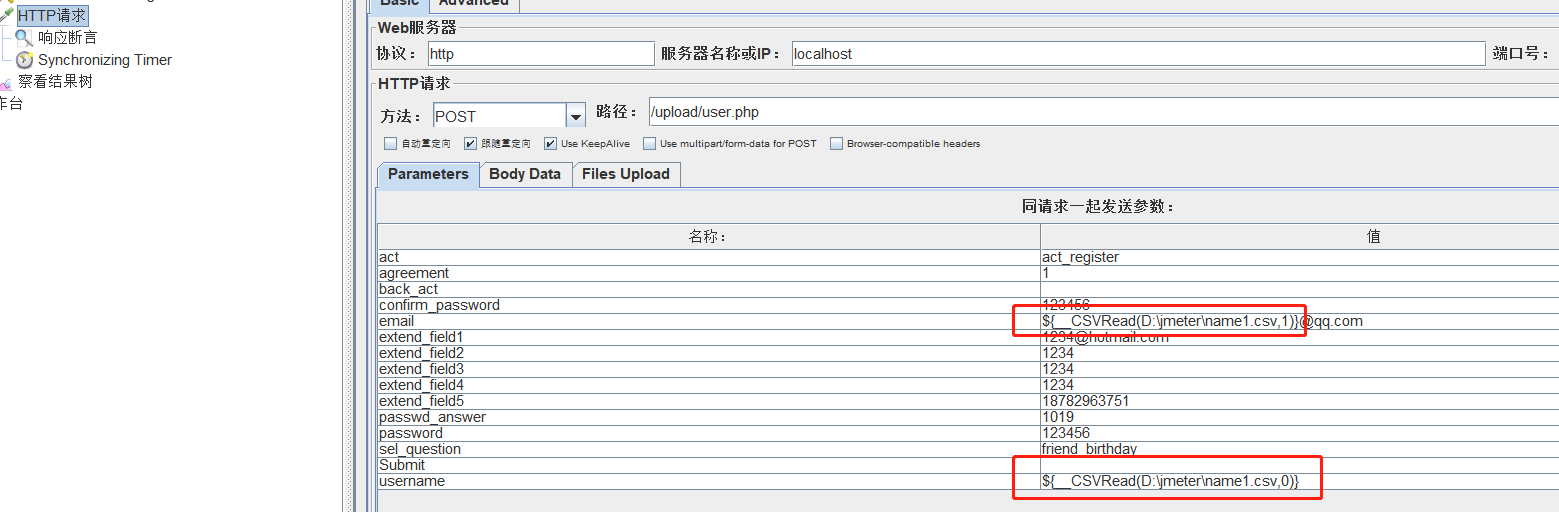
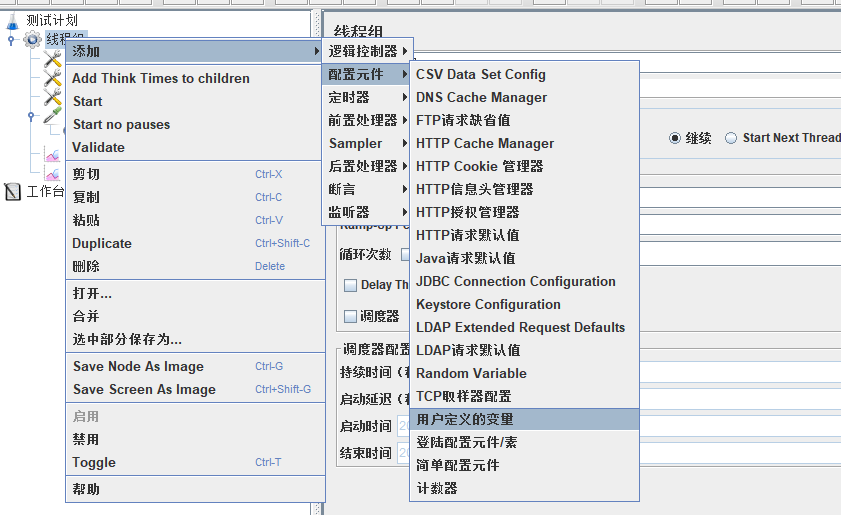
③ 用户自定义变量
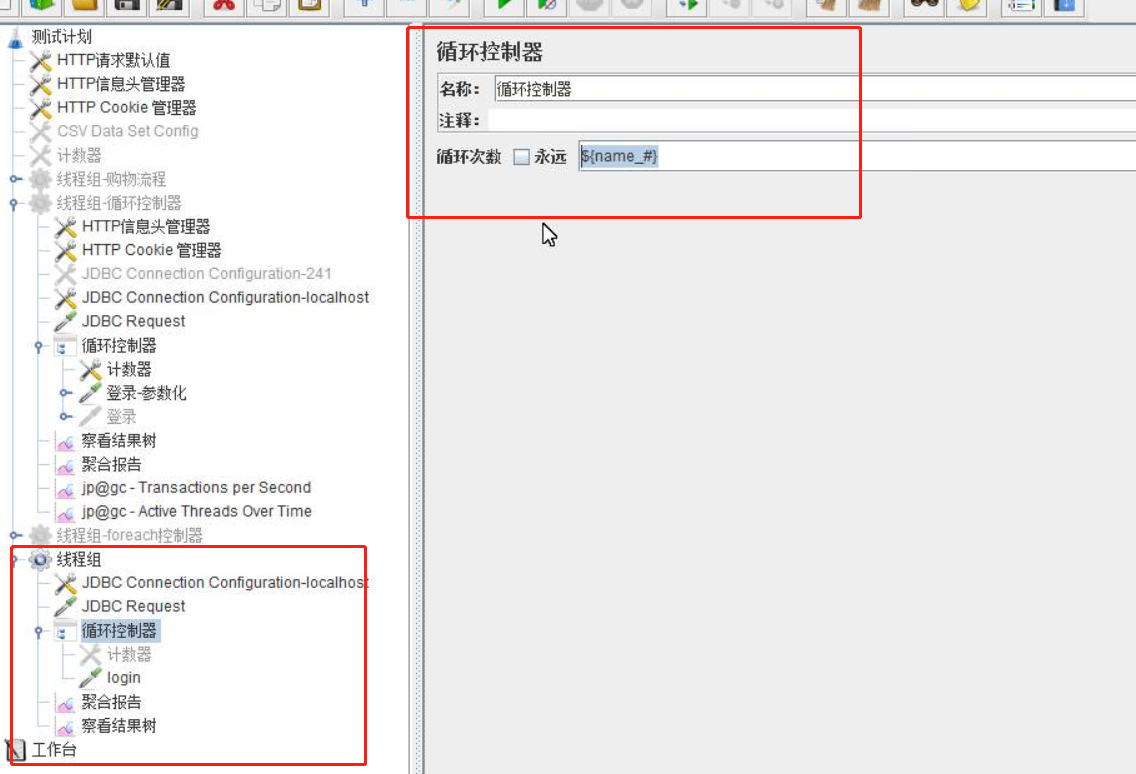
④计数器
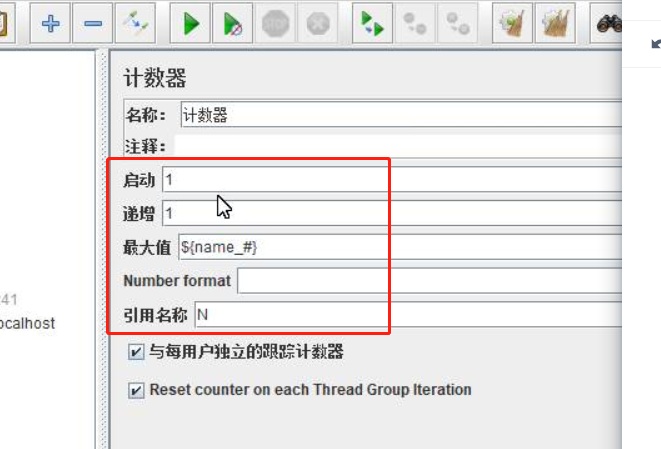
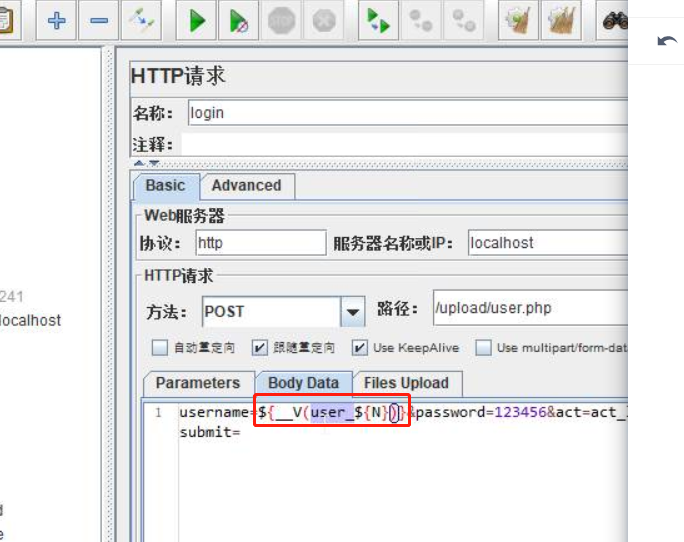
${__v(name_${N})} 两层变量用v函数,固定用法。
元件的作用域
- 配置元件
会影响其作用范围内的所有元件。
- 前置处理程序
在其作用范围内的每个sampler元件之前执行。
- 定时器
对在其所用范围内的每个sampler有效。
- 后置处理程序
在其作用范围内的每个sampler元件之后执行。
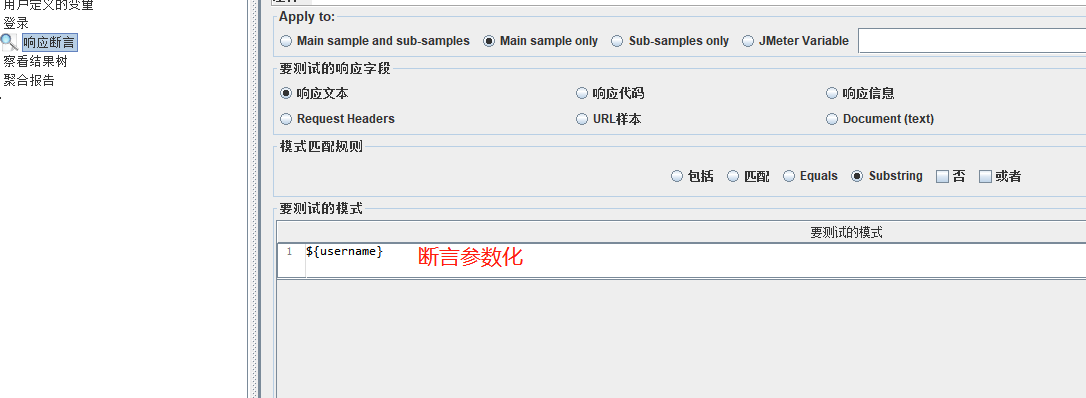
- 断言
在其作用范围内的每个sampler元件执行后结果进行校验。
- 监听器
收集其作用范围内的每个什么sampler元件的信息并呈现。
- 取样器
不予其他元件相互作用。
- 逻辑控制器
对其子节点中的去延期或逻辑控制器作用。
脚本开发
脚本录制
badboy
脚本生成
1.关联
关联:用于获取一个响应数据中的结果;
在后置处理器中-正则表达式提取器;
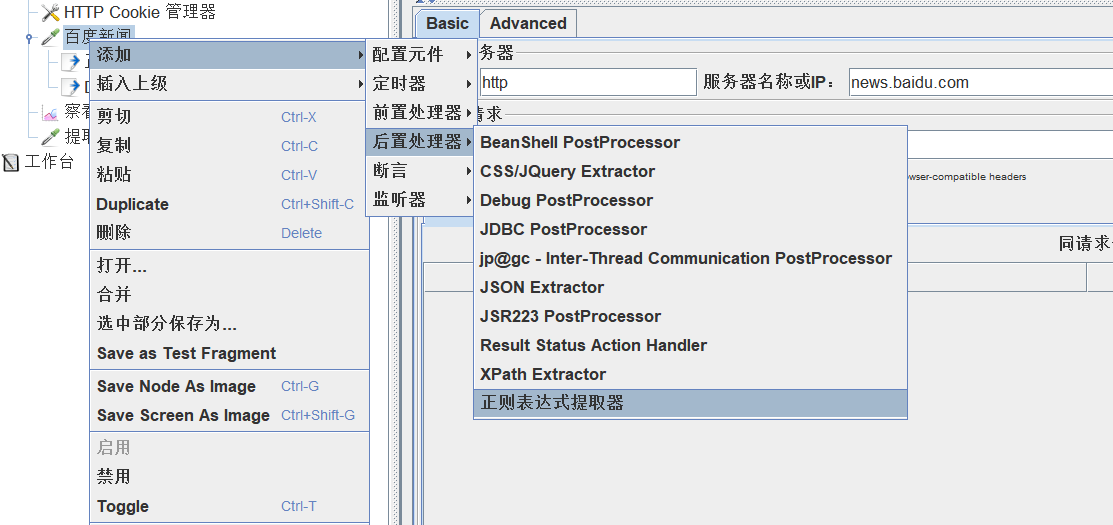
正则表达式
- 引用名称:下一个请求要引用的参数名称,
2.():括起来的部分就是要提取
. :匹配任何字符串
\+ :一次或多次
*:任意多次(可以取到空格)
?:不要太贪婪,在找到第一个匹配项后停止。3.模块:用$$引用起来,如果有多个()内容,可以用$1$,$2$等,标识解析到第几个值
4.匹配数字:0代表随机,-1代表全部,其余整整数代表提取第几个匹配的内容。
5.添加Debug进行调试
任意字符串的取法:(.+?)或(.*?)
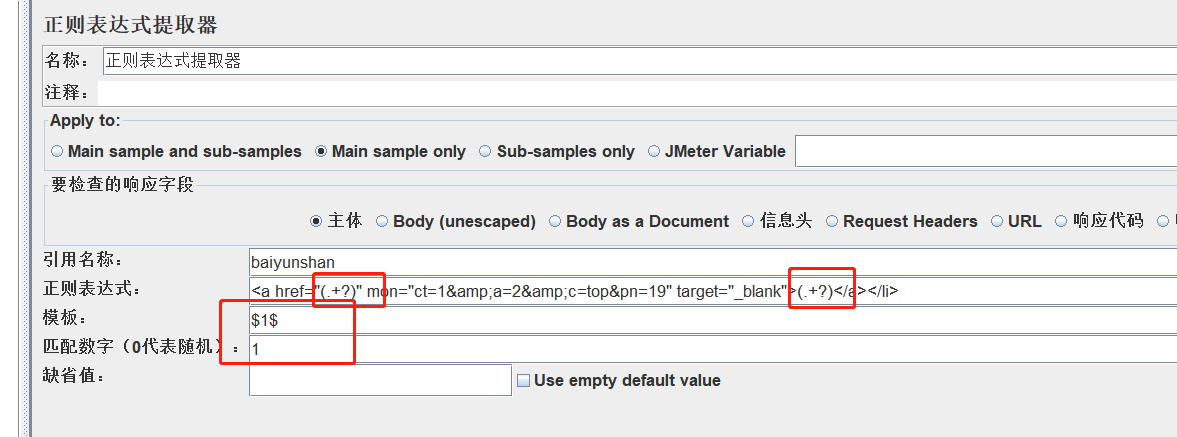
数字的取法:
([0-9]*),[0-9]表示取0-9的任意数字,*表示任意多次 ##表达式前面的字符不要太多
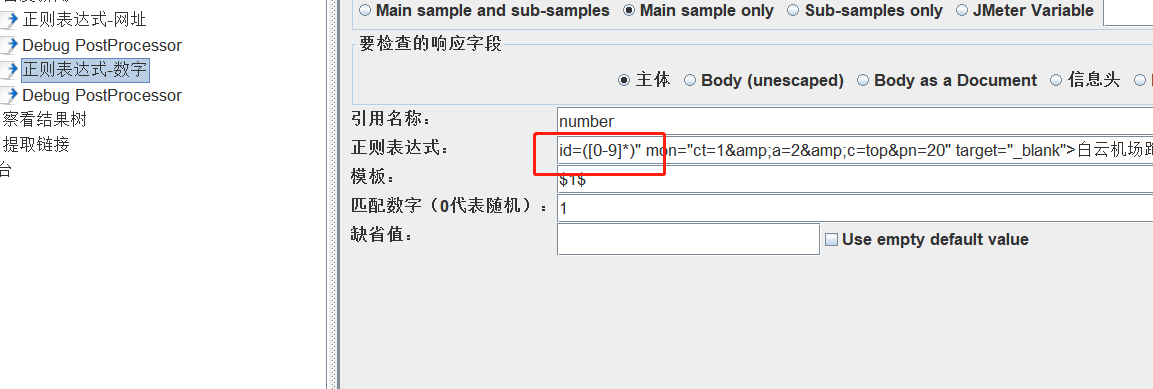
2.http请求默认值
有相同的服务器名称或IP地址时,将其填入请求默认值中,减小工作量。
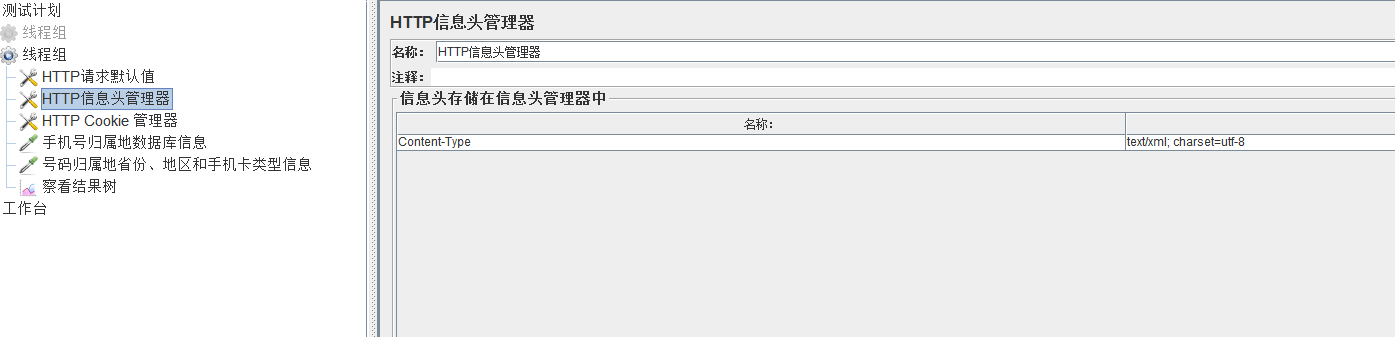
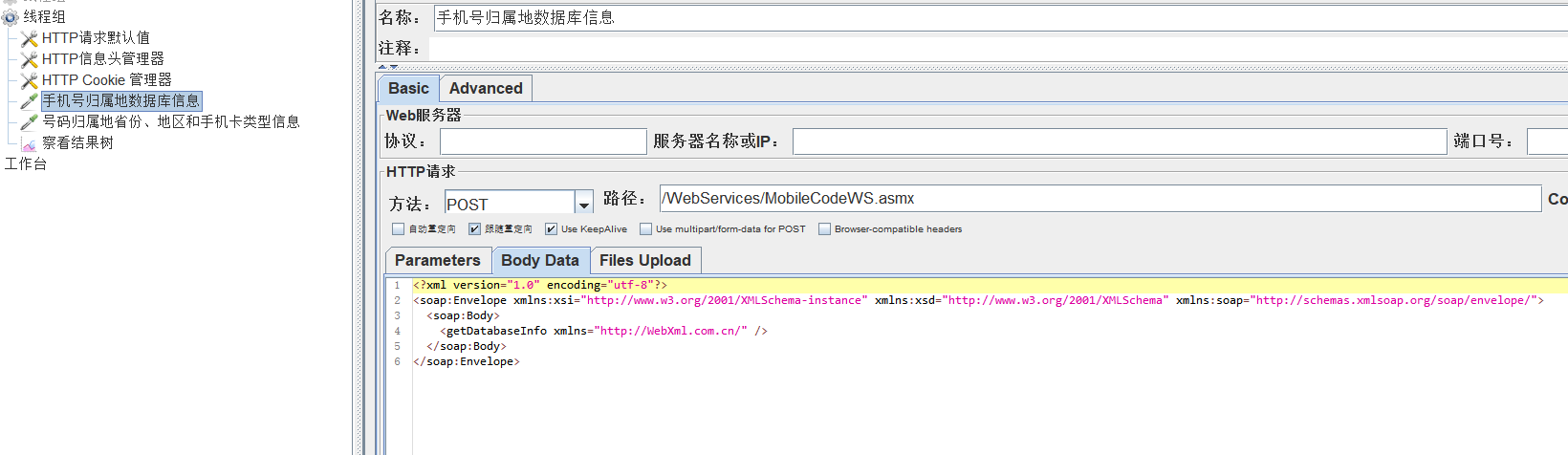
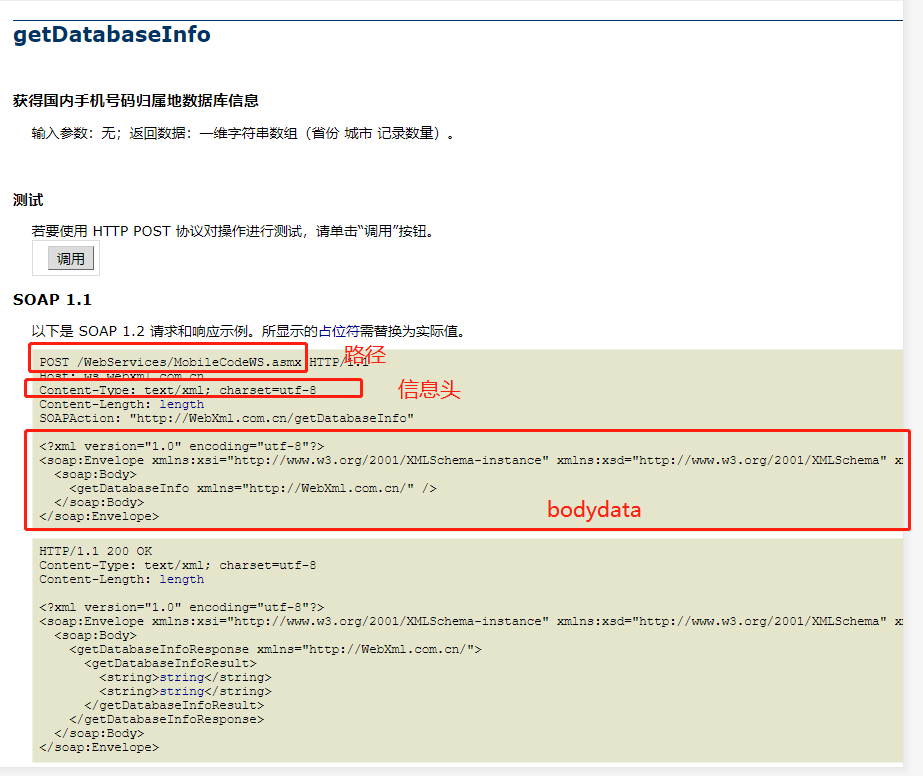
webservice接口测试
soap请求底层是调用的http请求
请求的报文是xml,返回的报文也是xml
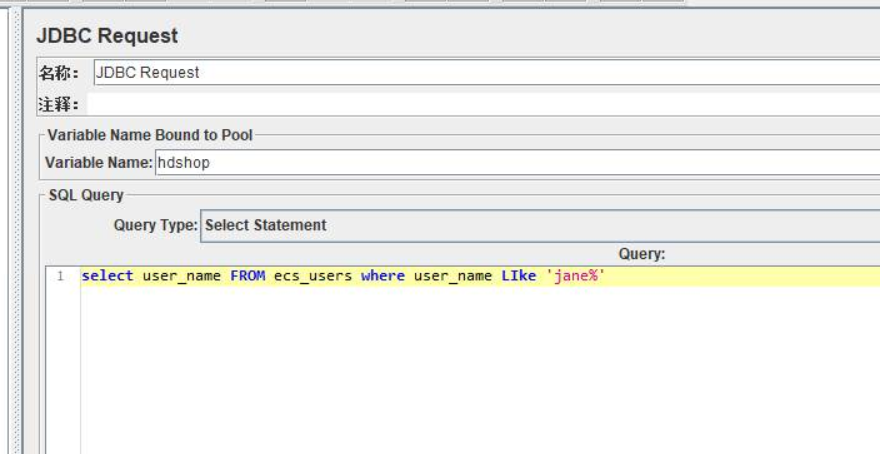
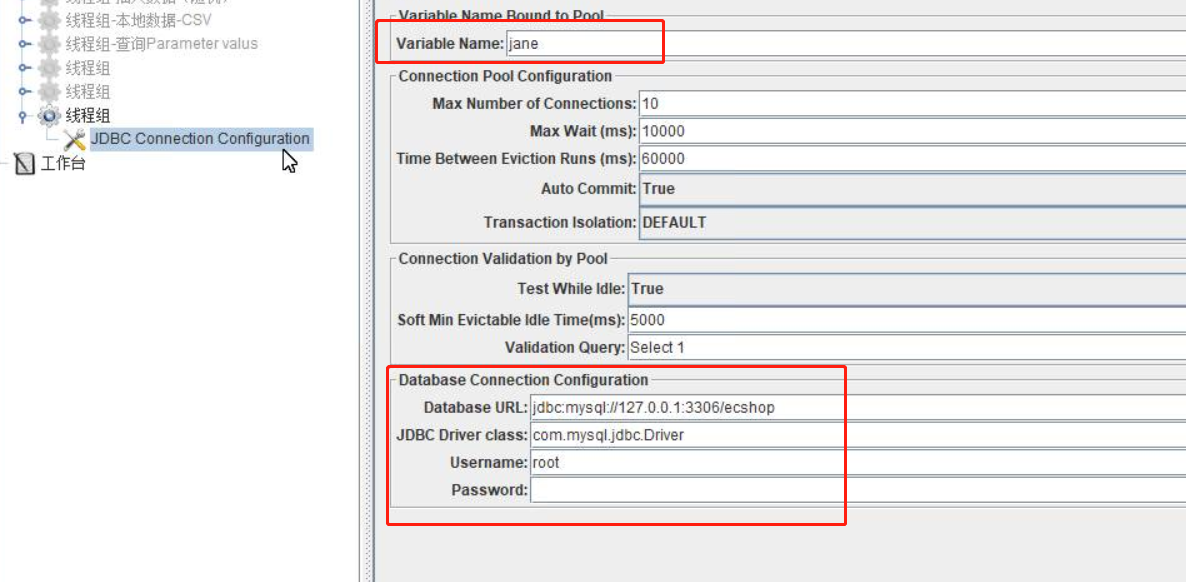
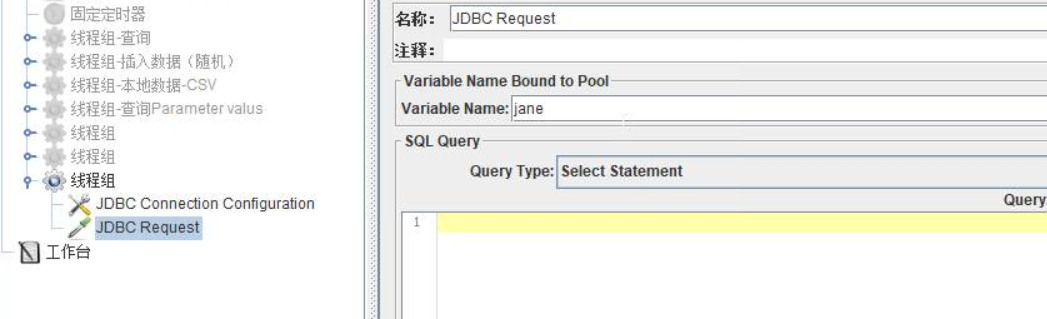
JDBC请求
- 添加控制元件,
JDBC Connection Configuration - 添加sampler ,
JDBC Request - 配置如下:
(1)Variable Name:变量名可自定义
(2)JDBC URL:jdbc:mysql://127.0.0.1:3306/ecshop
(3)JDBC Driver Class:com.mysql.jdbc.Driver
(4)username: 数据库名
(5)password:数据库密码
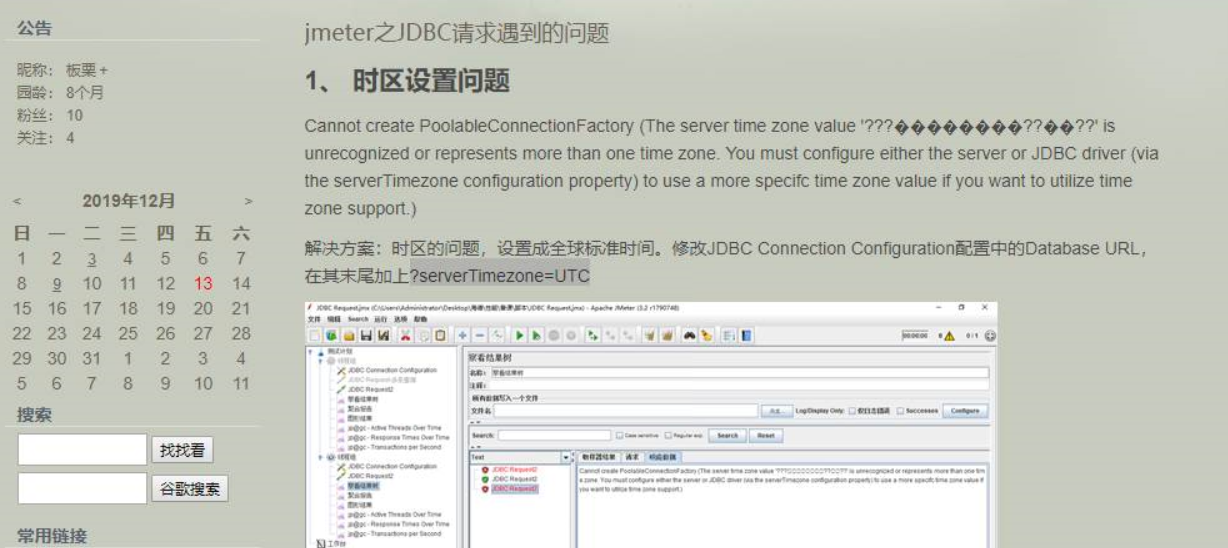
- 时区设置问题
在 URL 末尾加 ?serverTimezone=UTC
- 要添加多条
SQL语句
在 URL 末尾加 ?allowMultiQueries=true (前面有?的用&连接),JDBC Request 中
- 设置字符集类型
在URL末尾加 ?characterEncoding=UTF-8
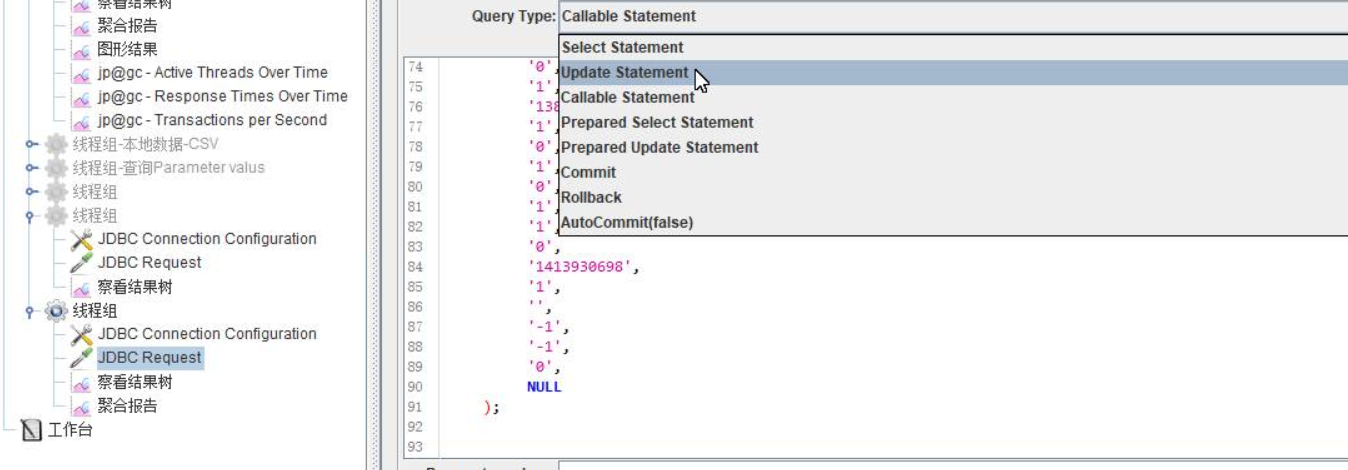
- 插入删除更新操作,
Query Type都选update Statement
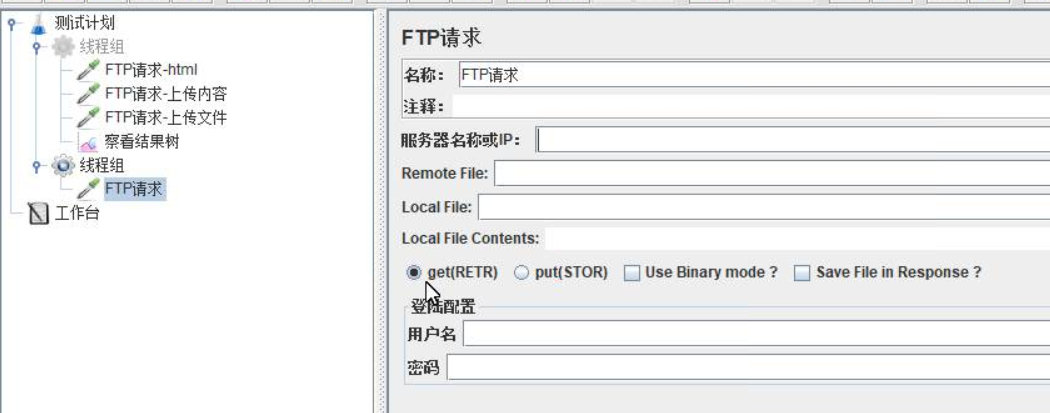
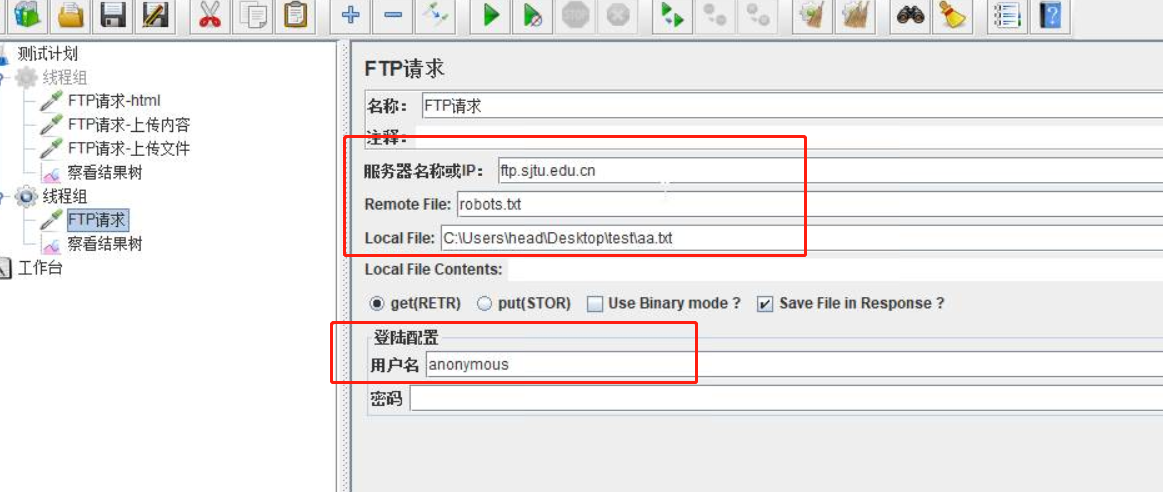
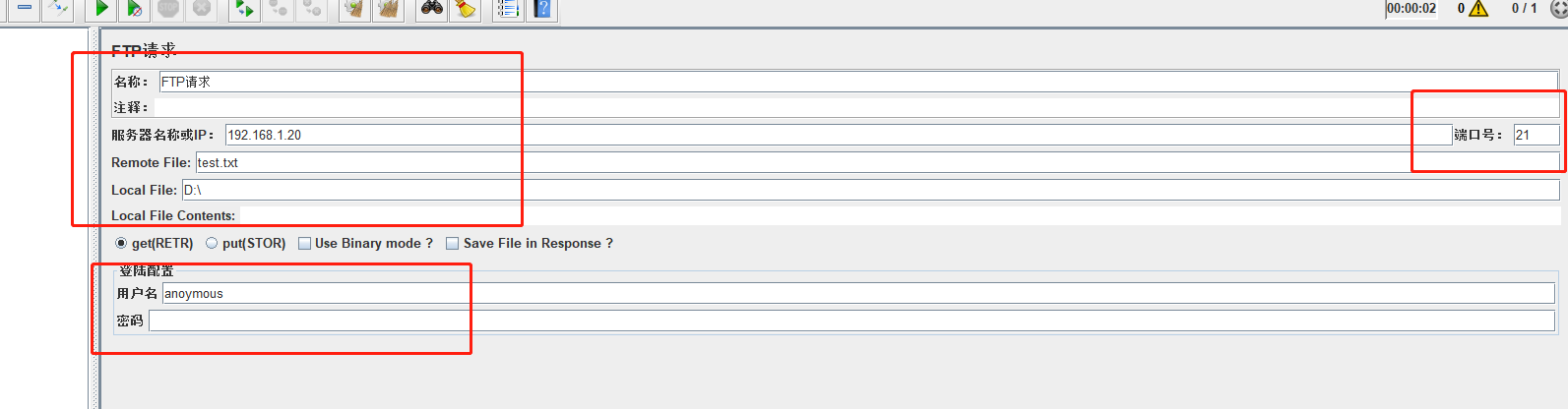
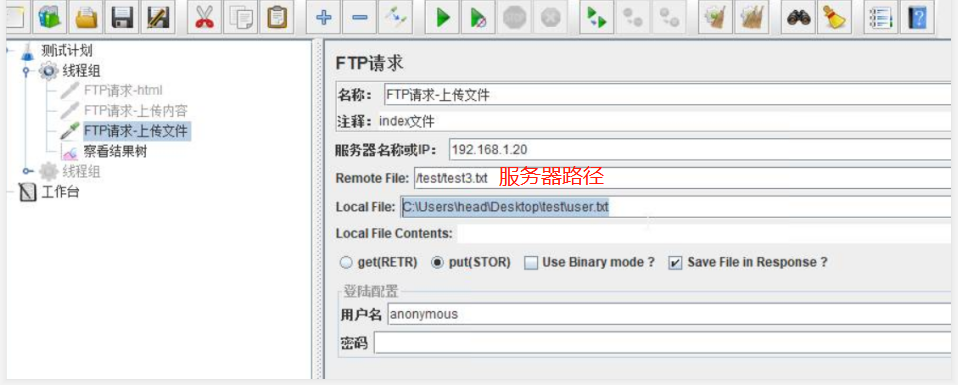
FTP请求
sampler中添加FTP请求- 配置如下
端口号:21
服务器名称和 IP:上传或用来下载的服务器地址
Remote File:远程 FTP 服务器文件路径(要加文件名)
Local File:本地文件路径(要加文件名)
Local File Contents:本地文件内容
用户名:如果是匿名用户登录,也要填入“anonymous”
密码:
场景设置
分布式运行
控制机:又称调度机,参与脚本的运行,主要是管理远程负载机,指挥远程负载机运行的任务,收集测试结果;
负载机:又称执行机,运行脚本的机子;
(1)分布式执行原理
①选择一台机器作为调度机,其他机器作为执行机
②执行时,master 会把脚本发送给每台 slave,slave 拿到脚本后执行,slave 执行时启动 jmeter-server.bat 即可(无需启动 Jmeter 软件)
③执行完后 slave 会把结果回传给 master
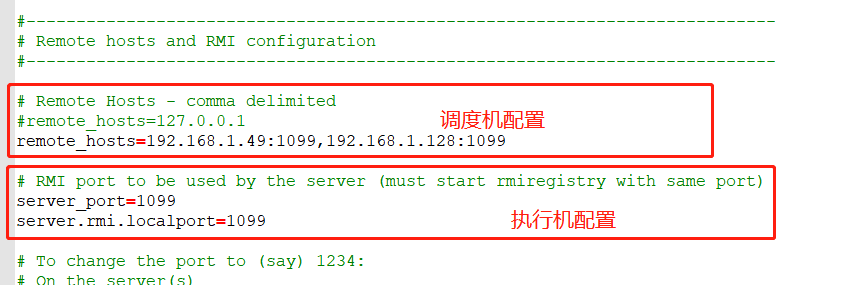
(2)分布式配置方式
①调度机(master)配置
仅需将自己的 IP 添加到配置文件里面就行
找到J
meter.properties在
remote_hosts后面加上负载机的 IP 地址
②执行机(slave)配置
找到
Jmeter.properties修改配置项(默认端口:1099)
shserver_port=1099 server.rmi.localport=1099启动
Jmeter-server.bat
③注意事项
软件版本要一致
三方配置文件要配置在负载机上,路径要一致
注册等特殊情况,分发给负载机的参数化文件,参数不能相同。
d.脚本不要放在桌面上
④如果连接失败需检查:
是否关闭了防火墙
是否禁用了所有的虚拟网卡
参数化的
CSV文件要复制到负载机上三方的jar包要复制到负载机上
浪涌测试
(1)概述
定义:浪涌测试是持续进行高强度和普通强度的交叉压力测试。
目的:主要是查看资源的释放情况。
(2)操作步骤
①在测试计划,右键添加 threads→Ultimate Thread Group
②添加以下测试策略数据:
Start Thread Count:开始线程数量Initial Ddlay,sec:线程加载多长时间开始运行Startup Time,sec:线程加载多长时间Hold Load For,sec:线程持续运行多长时间Shutdown Time:线程停止时长,在多长时间内停止下来。
IP欺骗
- 对电脑添加多个可用
IP,并将IP地址保存在一个txt或csv文档中 - 添加配置元件
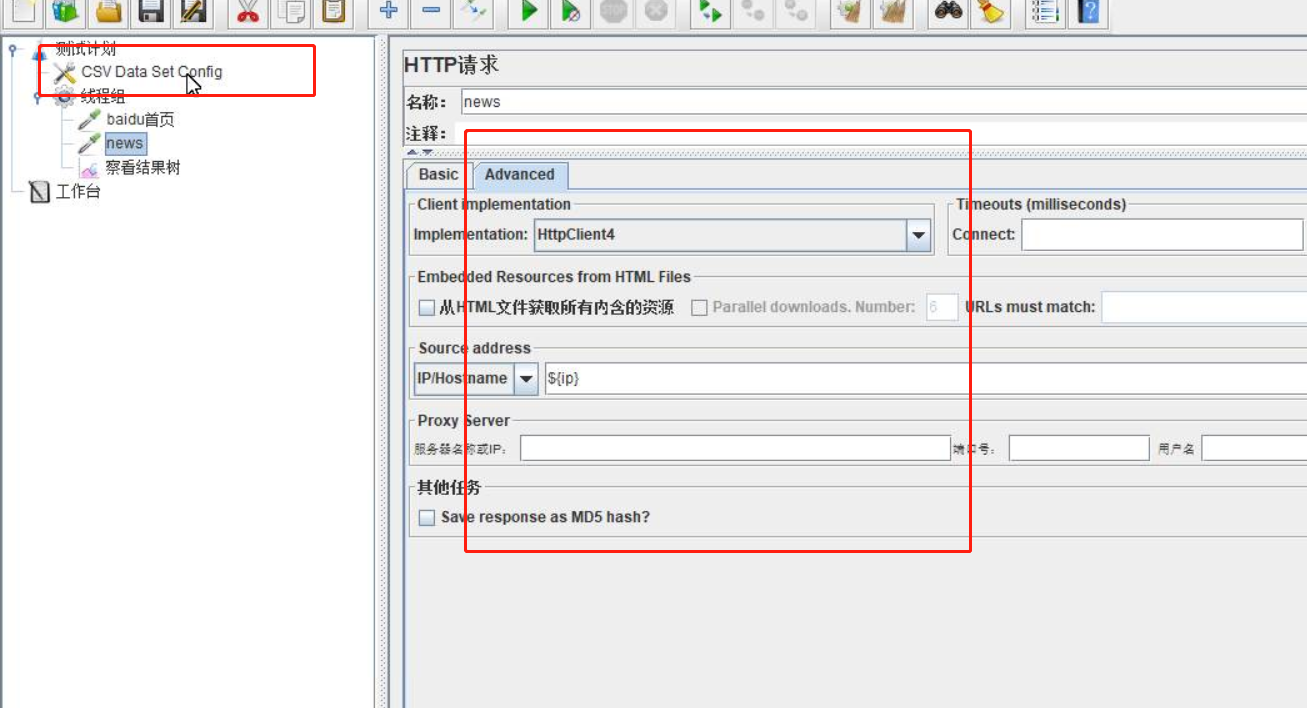
CSV Data Set Config将文档中IP参数化 - 在请求中选择
[Advanced],implementation选择HttpClient4,Source address选择IP/Hostname,并输入IP参数(${ip})
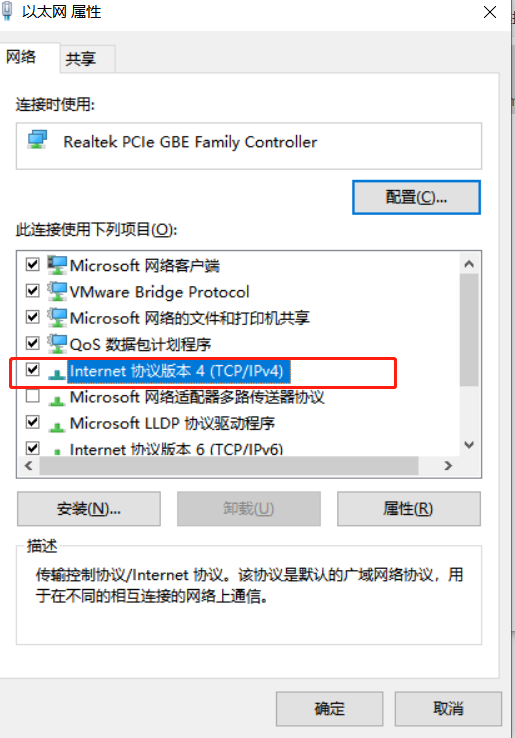
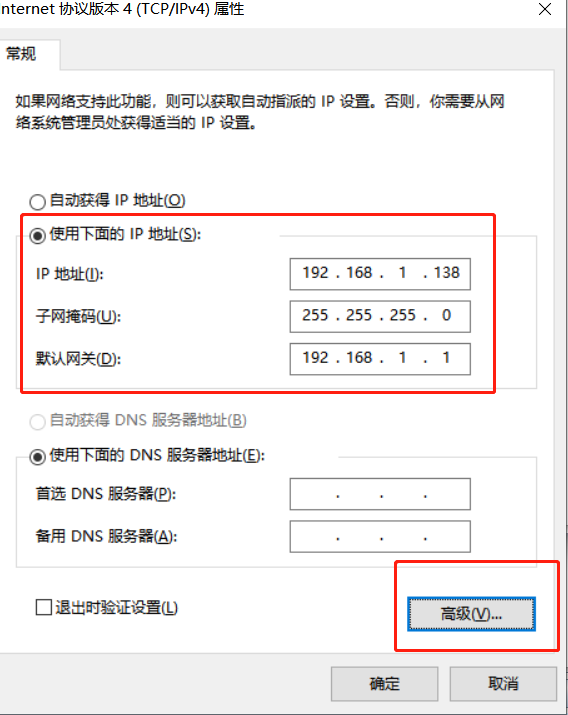
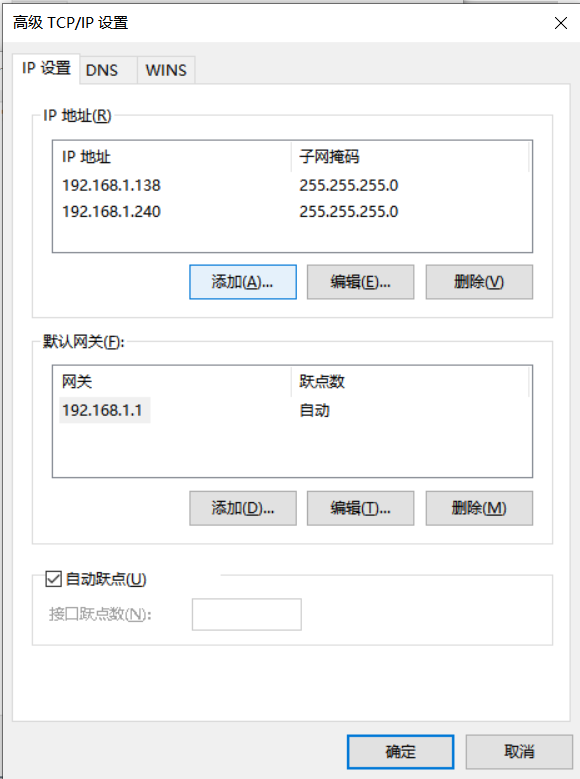
连不上网,需要把“首选 DNS 服务器”填上 192.168.1.1,
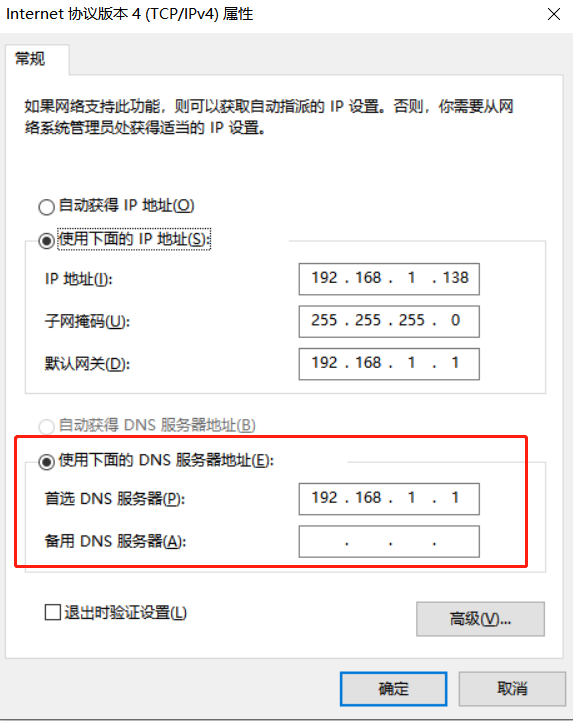
将网络禁用后重启;
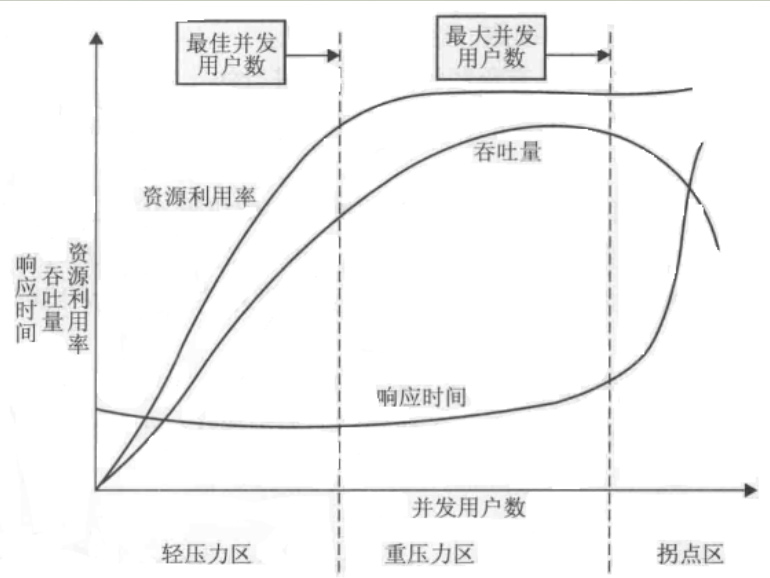
曲线拐点模型分析
1.定义
性能测试曲线模型是一条随着测试时间不断变化的曲线,与服务器资源,用户数或其他的性能指标密切相关的曲线。
2.解释
x轴代表并发用户数,Y轴代表资源利用率、吞吐量、响应时间。
从左往右依次为轻负载区、重负载区、拐点区
(1)响应时间:轻负载区变化不大,重负载区增长,拐点区倾斜率增大。
(2)吞吐量:轻负载区增加,重压力区逐步平稳,拐点区急剧下降。